
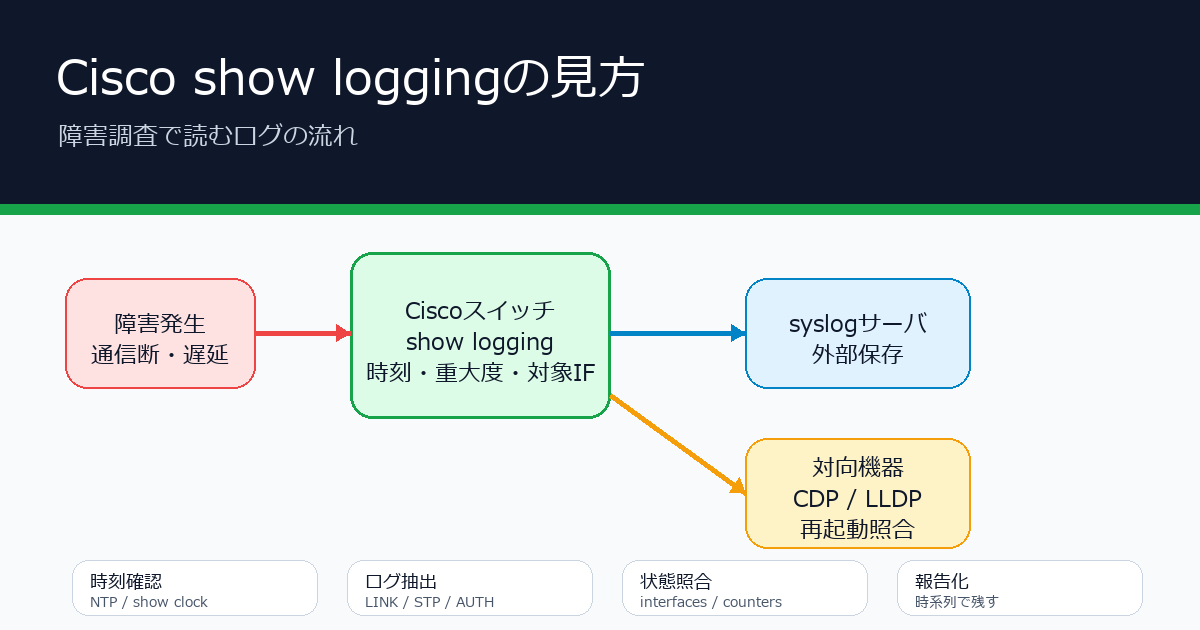
Cisco機器で障害調査を始めるとき、最初に見ることが多いのが show logging です。この記事では、L2/L3スイッチやルータで「リンク断があったのか」「STPが動いたのか」「認証に失敗しているのか」を10分で切り分けたい人向けに、ログの読み方と現場で見る順番を整理します。
対象は Cisco IOS / IOS XE の基本運用です。機種やバージョンで表示は少し違いますが、ログを読む時の軸は変わりません。時刻、重大度、対象インターフェース、直前直後の変化を並べると、単発のログが「物理断」「STP再計算」「認証失敗」「機器再起動」のどれに近いか見えてきます。
show loggingで最初に確認すること
いきなりエラーメッセージを探す前に、まず現在時刻とログ時刻が合っているかを見ます。NTPがずれていると、利用者から聞いた障害時刻とログが噛み合わず、原因候補を間違えます。次にログバッファの量、ログレベル、再起動有無を確認します。
show clock show logging show version | include uptime show running-config | include logging
以前、夜間に「一瞬だけ社内システムが重かった」という連絡を受けたことがあります。サーバ側を疑っていましたが、Ciscoのログを見ると同じ時間帯に上位スイッチ向けポートで link down/up が出ていました。NTPで時刻が合っていたため、サーバ処理遅延ではなくL2側の瞬断として早めに切り分けられました。
よく見るログと次に打つコマンド
Ciscoログはメッセージ単体で決めつけず、前後関係まで見ます。たとえば LINK-3-UPDOWN だけなら物理断の可能性がありますが、直後にSTPやEtherChannelのログが続くなら、単純なケーブル抜けではないことがあります。
| ログ例 | 疑うこと | 次の確認 |
|---|---|---|
| LINK-3-UPDOWN | 物理リンク断、SFP、対向再起動 | show interfaces status |
| LINEPROTO-5-UPDOWN | L2/L3状態変化 | show interfaces |
| SPANTREE | STP再計算、ループ、BPDU変化 | show spanning-tree detail |
| SEC_LOGIN / AUTH | SSHログイン失敗、AAA不調 | show users / show aaa servers |
ログに出ていないから障害がない、とは言い切れません。バッファサイズが小さい、ログレベルが低い、再起動で消えた、外部syslogにしか残っていない、というケースがあります。重要機器では、機器内ログだけでなくsyslog転送も前提にします。
障害調査で読む順番
ログは「いつ何が起きたか」を示す入口です。そこからインターフェース状態、エラーカウンタ、STP状態、対向機器のログへ広げます。片側のCiscoだけを見ると、対向サーバのNIC省電力、上位スイッチ再起動、メディアコンバータ瞬断、PoE給電の揺れを見落とすことがあります。
調査で使う頻度の目安
90%
85%
65%
show logging | include Gi1/0/24|Te1/1/1|Port-channel show interfaces Gi1/0/24 show interfaces counters errors show spanning-tree interface Gi1/0/24 detail show cdp neighbors detail
| 確認対象 | 見るコマンド | 判断のヒント |
|---|---|---|
| 対向機器 | show cdp neighbors detail | 接続先と管理IPを確認 |
| エラー増加 | show interfaces counters errors | CRC、drops、input errorを見る |
| 再起動 | show version | uptimeと障害時刻を照合 |
報告に残すべきログの形
障害報告では、ログを1行貼るだけでは足りません。「何時何分に、どのポートで、どの状態変化があり、対向側では何が起きていたか」まで残すと、再発時に比較できます。特に回線、上位スイッチ、サーバNICが絡む場合は、片側だけのログで結論を急がないほうが安全です。
2026-05-27 21:14:03 Gi1/0/24 link down 2026-05-27 21:14:07 Gi1/0/24 line protocol down 2026-05-27 21:14:19 Gi1/0/24 link up 対向: Server-01 NIC link renegotiationあり 影響: VLAN10の一部端末で約20秒の通信断
この形で残すと、次に同じポートで再発した時に「前回と同じか、違うか」を比べられます。Ciscoログは調査の入口ですが、最後は対向、物理、設定、利用者影響を同じ時系列に置くことで、原因候補が絞れます。
トラブル別のログの読み方
同じ show logging でも、見たい事象によって検索する文字列は変わります。リンク断だけを追うなら LINK や LINEPROTO が入口になりますが、ループ疑いなら SPANTREE、ログイン不調なら SEC_LOGIN や AAA を見ます。最初から全部読むより、事象に合わせて絞り込むほうが早いです。
| 事象 | include例 | 合わせて見る情報 |
|---|---|---|
| 瞬断・リンク断 | LINK|LINEPROTO | 対向ポート、SFP、CRC、PoE |
| L2ループ疑い | SPANTREE|MACFLAP | STP detail、MAC address-table |
| SSHログイン不可 | SEC_LOGIN|AAA|SSH | AAAサーバ、VTY、ACL |
| 経路変動 | OSPF|BGP|EIGRP | neighbor、route、CPU負荷 |
たとえば「一部の端末だけ数十秒切れた」という相談なら、まず該当VLANのアクセススイッチでリンク断とSTPを見ます。全体的に遅いなら、上位スイッチやルータ側でCPU、経路変動、エラー増加も見ます。ログの読み方は、単にエラー文字列を探す作業ではなく、影響範囲から見る機器を絞る作業です。
私は一次切り分けでは、まず障害時刻の前後5分を見ます。そこに何も出ていなければ、前後15分、同一上位配下、同じVLAN、同じポートチャネルへ範囲を広げます。最初から全ログを読むと時間がかかるので、利用者影響から逆算してログを見る順番を決めます。
もう一つ見落としやすいのが、ログに残る「最初の変化」と、利用者が感じた「最初の影響」が同じ時刻とは限らない点です。たとえばSTPの再計算は数秒で終わっても、端末側のアプリケーション再接続や名前解決の待ち時間で、利用者にはもっと長く感じられることがあります。ログ時刻だけで影響時間を決めず、監視アラート、サーバログ、利用者申告を並べるとズレを説明しやすくなります。
逆に、利用者申告の時刻が曖昧な場合は、Cisco側のログが起点になります。「何時ごろ」ではなく、リンク断、STP、経路変動、認証失敗のどれが最初に出たかを押さえると、調査対象を広げる方向が決まります。ここを曖昧にしたまま機器を順番に眺めると、原因に近づくまで時間がかかります。
そのため、私はログ確認のメモには必ず「最初のログ」「最大影響時刻」「復旧確認時刻」を分けて書きます。
ログレベルとsyslog保存の考え方
Ciscoのログは、出力される量と保存される量を分けて考えます。コンソール、VTY、バッファ、syslogサーバでログレベルが違うと、運用中に見ているログと、障害後に残っているログが一致しません。たとえば機器内のバッファが小さいままだと、ログが多い日に古い情報から消えていきます。
アクセススイッチのように台数が多い機器では、すべてを細かく保存するとsyslog側が読みにくくなります。一方で、コアスイッチ、WANルータ、ファイアウォール直下のL3スイッチは、短時間のリンク断でも影響が広く出ます。機器の役割によって「機器内で最低限見るログ」と「外部に必ず残すログ」を分けると運用しやすくなります。
show running-config | include ^logging show logging show ntp status show archive log config all
設定変更が絡む障害では show archive log config all も見ます。リンク断だけを追っていても、直前にインターフェース設定、VLAN、port-channel、STP priority が変わっていれば話が変わります。ログ、設定変更履歴、対向側ログの3つを合わせると、偶発的な物理断なのか、人の作業がきっかけなのかを切り分けやすくなります。
小規模な拠点でも、最低限「時刻同期」「外部syslog」「設定変更履歴」の3点は見える状態にしておくと、あとから調査しやすくなります。障害が起きてからログ保存を増やしても、すでに消えたログは戻せません。平常時に保存先とログ量を決めておくことが、結局いちばん早い切り分けにつながります。
まとめ
Ciscoの show logging は、障害調査の入口として使いやすいコマンドです。最初に時刻とログ保存状態を見て、LINK、LINEPROTO、STP、認証、再起動のログを前後関係で確認します。ログだけで結論を出さず、インターフェース状態、エラーカウンタ、対向機器の状態と合わせると、短時間で原因候補を絞れます。
よくある質問
Q. show loggingでログが少ない時は何を見ますか?
ログバッファサイズ、logging buffered のレベル、再起動有無、外部syslogの設定を確認します。機器内ログだけに頼ると古いログが消えることがあります。
Q. LINK-3-UPDOWNが出たらケーブル不良ですか?
可能性はありますが、対向機器再起動、SFP、STP、EtherChannel、電源瞬断でも似たログになります。前後のログと対向側の状態を合わせて見ます。
Q. show loggingだけで原因を断定できますか?
断定できないことが多いです。ログで時刻と対象を絞り、インターフェース状態、エラーカウンタ、STP、対向機器ログで裏取りします。
