
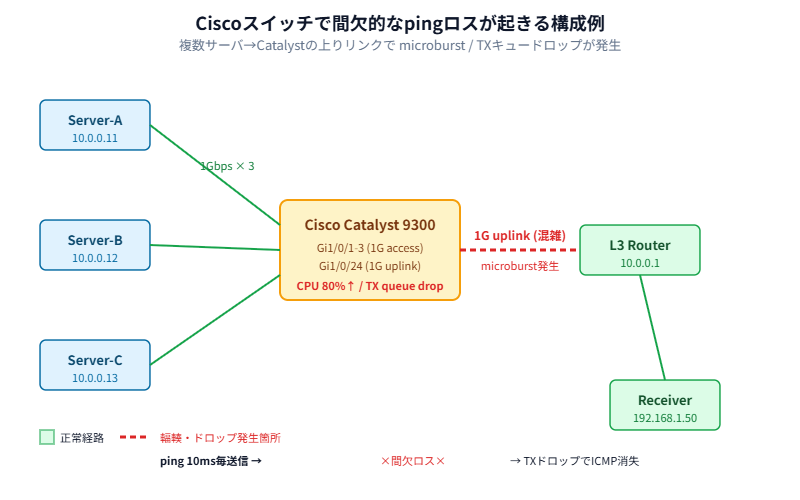
深夜のメンテ明け、ふだんは静かなセグメントから「pingが時々こけてる」とSlackが飛んできた。実際に打ってみると、100発中に1〜3発だけタイムアウトする。完全に切れるわけじゃない、でも確実に何か起きてる。これ、ネットワークエンジニアの一番嫌な状況です。
この記事ではCiscoスイッチで間欠的なpingロスが発生したときの「現場での切り分け順序」と、microburst・QoSドロップ・CPU高負荷という3つの主犯を実機コマンドで突き止める手順をまとめます。完全に切れるパケットロスではなく、グラフでギザギザに揺れるあの厄介な症状に的を絞って解説。
完全断線とは何が違うのか
完全に通信断なら話は早い。リンクダウン、STPの収束、HSRPフェイルオーバー、このあたりを順番に潰せば原因にたどり着く。やっかいなのは「ほとんどのパケットは通るけど、たまに落ちる」パターン。これが間欠ロスです。
で、現場でこう聞かれることが多い。「pingは通ってるんだから、ネットワーク側じゃないですよね?」と。違います。1%のロスでも、TCPの再送が走るとアプリの応答時間は数倍に膨れ上がる。VoIPなら音声がプチプチ切れる。間欠ロスは無視できない症状です。
以前、客先でファイルサーバへの転送が「妙に遅い」と相談を受けたことがあって。pingで監視したら100発中2発くらいタイムアウト。最初はLANケーブルを疑ったけど、結局はバックアップジョブが朝7時に走るタイミングで上りリンクがmicroburstを起こしてた。原因まで2日かかった。地味に消耗した案件です。
間欠ロスの典型パターン3つ
経験上、Ciscoスイッチで間欠ロスが出るときの主犯はだいたい以下の3つに収束します。
| パターン | 特徴 | 主な確認コマンド |
|---|---|---|
| microburst (TXキュードロップ) | 平均使用率は40%程度なのにバーストで100%瞬間的に張り付き、output dropsがじわじわ増える | show int […] | inc drop |
| QoSドロップ | 特定のクラス(音声・映像など)だけが落ちる、平時は問題ないが業務時間にだけ出る | show policy-map int |
| CPU高負荷 (CPU punt) | スイッチ自体宛のpingだけ落ちる、SNMPポーリングでさらに悪化する | show proc cpu sorted |
「ロス=物理層の異常」と決めつけてケーブル交換から始めると遠回りします。間欠ロスの場合、まずはshow interfacesでoutput dropsとinput errorsをセットで見るのが正攻法。物理層の話はその後で十分。
microburstはなぜ厄介か
microburstとは、ms単位の超短時間で帯域が瞬間的にフルに張り付く現象のこと。SNMPやNetFlowで5分平均を見てると「使用率30%しかない、問題ないでしょ」と片付けられがち。でも内部のTXキューは数msで溢れて、確実にパケットを捨てています。
典型的な発生源はこのあたり。バックアップジョブ、ストレージのスナップショット転送、仮想マシンのvMotion、Windows Updateの社内配信、監視サーバの一斉ポーリング。どれも「短時間で大量のパケットを流す」処理です。
図1: 平均使用率とmicroburstの差(上りリンク観測例)
32%
55%
100%
同じリンクでも観測粒度を細かくすると、ピーク値はまったく違う絵になる。SNMPで安心するのは罠です。
QoSドロップの特定が必要な場面
QoSポリシーをかけている環境では、特定クラスだけが優先的に落とされて間欠ロスとして見えることがあります。例えばDSCP EFの音声トラフィックは保護されてるけど、デフォルトクラス(class-default)に分類されたICMPは真っ先にドロップ対象になる。
ここで重要なのは「ping(ICMP)はテスト用と思われがちで、QoSの優先度は最低クラスに置かれることが多い」という事実。本番のTCPアプリは普通に動いてるのに、pingだけ落ちる。これはQoS設計の典型的な副作用です。
QoSポリシーの動作は show policy-map interface で出力できる。class-default の drops カウンタが増え続けてたら、ICMPがそこに落ちてる可能性が高い。
CPU高負荷 (Control-plane punt)
「スイッチ自身宛のping」だけが間欠的に落ちるなら、CPU高負荷を疑うべきです。Ciscoスイッチは通常パケットをハードウェアで転送しますが、自分宛のpingやSSH、SNMPは制御プレーン(CPU)で処理する。CPUが詰まると、これらの応答が間に合わず落ちます。
CPU負荷の主な原因は、過剰なARP/MACラーニング、不正なルーティングプロトコルパケット、SPANポートの設定ミス、それからTrap・Syslogの大量発生。あと、設計時には想定してなかったマルチキャストトラフィックがCPU処理に飛んでくるパターンもよくある。ぶっちゃけ、これが一番診断に時間がかかります。
調査前にそろえておきたい情報
| 確認項目 | なぜ必要か |
|---|---|
| 送信元IP / 宛先IP | スイッチ自身宛か、それとも通過するパケットか — 切り分け方が変わる |
| 発生時刻と頻度 | バックアップ・バッチ・業務ピークなど時間帯依存性を見る |
| 経路上のスイッチ全台数 | どこで落ちてるか特定するため、ホップごとに調査 |
| QoSの有無 | policy-mapが入ってるなら、ICMPの分類先を確認する |
| CPU使用率の推移 | CPU pinned かどうかで原因のアタリが大きく変わる |
Switch# show interfaces GigabitEthernet1/0/24 | include drops|errors|rate
5 minute input rate 312000 bits/sec, 421 packets/sec
5 minute output rate 875000 bits/sec, 1102 packets/sec
0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored
0 output errors, 0 collisions, 0 interface resets
Output queue: 0/40 (size/max)
Total output drops: 14523
ここで Total output drops が増え続けてたら、microburstかキューサイズ不足の可能性が高い。input errorsも0、CRCも0なら物理層は無罪です。次にQoSとCPUを見にいきます。
Switch# show platform hardware fed switch active qos queue stats interface Gi1/0/24 DATA Port:24 Enqueue Counters Q Buffers Enqueue-TH0 Enqueue-TH1 Enqueue-TH2 0 0 0 12305201 0 1 0 0 45821 0 DATA Port:24 Drop Counters Q Drop-TH0 Drop-TH1 Drop-TH2 SBufDrop QebDrop 0 0 0 9824 0 0 1 0 0 0 0 0
Catalyst 9000系ならこのコマンドでハードウェアキュー単位のドロップが見える。Drop-TH2が増えてたら、しきい値超過のドロップが起きてる証拠。Cisco IOSやCatalystのモデルによってコマンドが違うので、自環境では show platform ? で補完しながら探してください。
show platform 系のコマンドはCPU負荷を一時的に上げます。本番機で連続実行するときは間隔を5秒以上空けるのが安全。短時間に何度も叩くと、それ自体がCPU pinnedの原因になりかねない。
Switch# show processes cpu sorted | exclude 0.00 CPU utilization for five seconds: 78%/45%; one minute: 62%; five minutes: 41% PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process 158 4521203 23415021 193 18.27 12.33 8.41 0 IP Input 312 3210551 14523011 220 11.05 9.21 6.55 0 ARP Input 88 1820305 8451203 215 7.42 5.18 4.02 0 HSRP IPv4
「78%/45%」の意味、これ意外と知らない人が多いんですが、左がCPUトータル、右が割り込み(interrupt)です。割り込みが30%超えてたら、ハードウェア転送できないパケットが大量にCPUに上がってきている = “punt” 状態を疑う。IP InputやARP Inputが上位を占めるなら不正なARPやARPストームの可能性も。
Switch# show policy-map interface Gi1/0/24
GigabitEthernet1/0/24
Service-policy output: WAN-OUT
Class-map: VOICE (match-any)
12503012 packets, 1820100012 bytes
Match: dscp ef (46)
Class-map: class-default (match-any)
45120311 packets, 38201205112 bytes
queue limit 272 packets
(queue depth/total drops/no-buffer drops) 0/8721/0
class-default の total drops がじりじり増えてたら、QoSが原因でICMPが落ちてる証拠。VOICEクラスのdropsが0なのを併せて見ると、QoSが設計通りに動いてるんだけど、ICMPがdefaultに落ちてる事実が見えてくる。
Switch# ping 192.168.1.50 repeat 1000 timeout 1 size 1500 Type escape sequence to abort. Sending 1000, 1500-byte ICMP Echos to 192.168.1.50, timeout is 1 seconds: !!!!!!!!!!!!!!!!!!!!!!!!!!!.!!!!!!!!!!!!!!!!!!.!!!!!!!!!!!.!!! [省略] Success rate is 97 percent (970/1000), round-trip min/avg/max = 1/2/8 ms
size 1500 で打つと、フラグメント・MTUの絡みも併せて見られる。ロスが3%程度なら、MTU不一致や物理層よりキュードロップの可能性が高い。10%以上なら物理層やケーブル不良も疑う。
microburst対策
短期的にできるのはキューサイズの拡張と、必要ならポートチャネル化による帯域追加。長期的には、バーストの発生源(バックアップサーバ等)にレートリミットをかけるか、専用VLAN/専用ポートで物理的に隔離してしまうのが王道です。
! TXキューサイズ拡張の例 (Catalyst 9000) Switch(config)# interface GigabitEthernet1/0/24 Switch(config-if)# queue-limit 4096
QoSドロップ対策
ICMPがclass-defaultに落ちて困るなら、ICMPだけ別クラスに切り出して最低保証帯域を確保する。例えばこんな感じ。
Switch(config)# class-map match-any ICMP-MGMT Switch(config-cmap)# match protocol icmp Switch(config)# policy-map WAN-OUT Switch(config-pmap)# class ICMP-MGMT Switch(config-pmap-c)# bandwidth percent 5
CPU高負荷対策
原因プロセスがARP InputならDAI(Dynamic ARP Inspection)で不正ARPを止める、IP InputならCoPP(Control-Plane Policing)を入れて制御プレーン宛トラフィックを制限する、というのが定石です。SNMP/Syslogの過剰送信が原因なら、ログレベルを下げて余計な出力を切るだけで負荷が劇的に減る場合もある。
CoPPは強力ですが、設定を間違えると正規のSSHやSNMPまで止めてしまう。本番投入前は必ず検証環境で show policy-map control-plane でカウンタを観測して、何が落ちてるかを確認する習慣をつけたほうが安全。
| 症状 | 疑うべき原因 | 確認コマンド |
|---|---|---|
| 通過pingが間欠ロス | microburst / QoS | show int / show policy-map int |
| スイッチ宛pingだけ落ちる | CPU高負荷 / CoPPドロップ | show proc cpu sorted |
| CRC/input errorが増える | 物理層・SFP・ケーブル | show int […] counters errors |
| 特定VLANだけ通信不安定 | MAC Flapping / STP収束 | show mac address-table |
間欠pingロス調査の要点
間欠pingロスは「物理層が悪い」と決めつけず、まずshow interfacesでoutput dropsを見るのが正解。dropsが増えてるならmicroburstかQoS、スイッチ宛pingだけ落ちるならCPU高負荷を疑う。SNMPの5分平均だけ見て安心しないこと、これが一番大事。原因が特定できたら、キューサイズ調整・QoSのICMP分類見直し・CoPPで対処していく。
よくある質問(FAQ)
Q. SNMPでは使用率30%なのにoutput dropsが増えるのはなぜ?
SNMPの5分平均はバーストを平均化して隠してしまうため。10ms単位ではフルに張り付いていて、TXキューがあふれている可能性が高いです。NetFlow/IPFIXか、より細かい粒度の監視ツール(Telemetry等)で観測しないと見えません。
Q. ping size 1500とsize 100でロス率が違うのは?
大きいパケットはMTU・フラグメント・キューバッファ消費に敏感。サイズを変えてロス率の差を見ると、MTU問題かバッファ問題かの切り分けに使えます。size 1500で大きく落ちて、size 100で落ちないなら、経路上のMTU不整合かバッファ不足が主犯と考えていい。
Q. CPU使用率はどのくらいから危険?
経験的に5秒値が継続して50%超え、または割り込み(右の値)が30%超えなら警戒ライン。Catalyst 9000系は普段はCPU 10〜20%程度のことが多く、急に50%以上で張り付いてるなら何かが起きてる。show processes cpu history でグラフ表示して、上昇のタイミングを把握するのがおすすめです。
Q. 経路の途中でロスしてるか、終端でロスしてるかを調べる方法は?
tracerouteを連続実行して、どのホップでロスが出るかを見る。ただしtracerouteは経路上のルータ宛にICMP/UDPを打つので、CPU pinned のルータが間に挟まると本来の問題と切り分けにくい。可能ならホップごとにpingを直接打って、どこから先で落ちるかを地道に確認します。
