「主回線がダウンしてるのに、ルータは何事もなかったように主経路にパケットを流し続ける」——これ、現場で一度はやらかすやつ。物理リンクは生きてるのに上流ISPだけ死んでる、みたいなケースはfloating static routeだけじゃ守れない。
そこで使うのが IP SLA と track の組み合わせ。実際に外部の宛先まで疎通確認させて、ダメだったらルートやHSRPのpriorityを動かす。この記事ではIP SLAの設定手順、track連携、HSRP・Static Routeとの結びつけ方、確認コマンドまで、Catalyst 9300とISR 4321で検証しながらまとめた。
IP SLAは「ルータから能動的に疎通を試す機能」
IP SLA(Internet Protocol Service Level Agreement)はCisco IOSの組み込み機能で、ルータ自身が能動的にICMPやUDP、HTTP、DNSなどのプローブを投げて応答時間や成否を測定する仕組み。リンクのup/downでは検出できない「先方まで本当に届いているか」を継続的に監視できる。
昔は「Service Assurance Agent (SAA)」という名前だった。古いConfigやベテランの先輩から「SAAで監視してる」と言われたら、それはIP SLAのこと。RFC 2925のpingMIBや、Ciscoの公式ドキュメントに詳細がある。
以前、客先で主回線のONUが「リンクは上がってるけど通信は死んでる」状態になったことがあった。ルータはGi0/0をupと判定してるからfloating staticは動かない。結局5分くらい外向き通信が止まって、慌ててIP SLA + trackに作り替えた。あれ以来、外向きルートの監視は「物理だけじゃダメ、必ず宛先到達性まで見る」が口癖。
代表的な4つの使い方
IP SLA単体で使うことはほとんどなくて、たいていtrackやHSRP、EEMと組み合わせる。ぶっちゃけ覚えるべきパターンはこの4つでだいたい足りる。
| 用途 | 組み合わせ | 何を実現するか |
|---|---|---|
| 経路監視 | IP SLA + track + Static Route | 主回線NG時に副回線へ自動切替 |
| FHRP連動 | IP SLA + track + HSRP/VRRP | 上流障害時にActive側を降格させて切替 |
| SLA測定 | IP SLA jitter/UDP echo | 遅延・ジッタ・パケロスを長期記録 |
| EEM連動 | IP SLA + track + EEM applet | 障害検知時に通知や自動コマンド実行 |
floating staticとの違いはここ
floating staticは「経路の優先度を変えるだけ」で、検出のトリガーは結局ネクストホップの到達性に依存する。IP SLA + trackなら、宛先まで届かなければ何が起きていようと切り替わる。
図1: 障害検知の精度比較(体感ベース)
92%
55%
30%
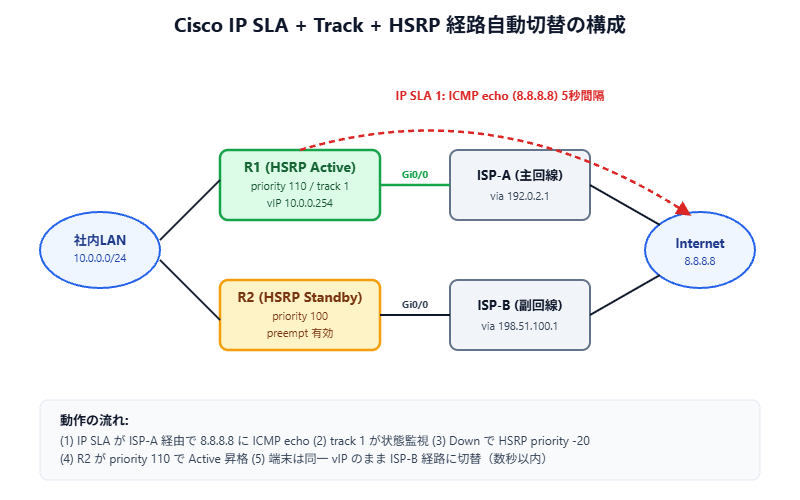
この章で作るもの
構成図の通り、R1(HSRP Active)から8.8.8.8へICMPを5秒間隔で打ち、3回連続で失敗したらtrackをDownにする。Down検知でHSRP priorityが−20されてR2が昇格、ユーザー端末は同じvIP宛で副回線(ISP-B)経由に切り替わる、という流れ。
| パラメータ | 設定値 | 備考 |
|---|---|---|
| SLA番号 | 1 | 機器内ユニーク |
| 監視先 | 8.8.8.8 | ISP-A経由で抜ける宛先 |
| 送信元IF | Gi0/0 | 主回線側を明示指定 |
| frequency | 5秒 | 短すぎるとCPU負荷上がる |
| timeout | 2000ms | 遠隔地なら3000推奨 |
| track delay | down 10 / up 30 | フラッピング防止 |
R1(config)# ip sla 1 R1(config-ip-sla)# icmp-echo 8.8.8.8 source-interface GigabitEthernet0/0 R1(config-ip-sla-echo)# frequency 5 R1(config-ip-sla-echo)# timeout 2000 R1(config-ip-sla-echo)# threshold 1500 R1(config-ip-sla-echo)# exit R1(config)# ip sla schedule 1 life forever start-time now
ポイントは source-interface を必ず明示すること。これを書かないと再帰ルックアップでISP-B側から抜けてしまうことがあって、肝心の主回線監視にならない。
ip sla schedule 1 life forever start-time now を入れ忘れるとプローブが永遠に動かない。show ip sla statisticsで「Operation timeout (in milliseconds): … Number of successes: 0」のままならまずこれを疑う。あとIOS 12.4以前は ip sla monitor という旧コマンドなので、古い機器を触るときは注意。
R1(config)# track 1 ip sla 1 reachability R1(config-track)# delay down 10 up 30 R1(config-track)# exit
delayの「down 10」は、SLAがDownになっても10秒待ってからtrackをDownにするという意味。瞬断でフラフラ切り替わるのを防げる。upを長めにしてあるのは、復旧直後の不安定な状態でまた切り戻して再障害になるのを避けるため。正直なところ、現場ではdown 5〜15、up 30〜60くらいで運用してることが多い。
R1(config)# interface Vlan10 R1(config-if)# standby 10 ip 10.0.0.254 R1(config-if)# standby 10 priority 110 R1(config-if)# standby 10 preempt R1(config-if)# standby 10 track 1 decrement 20
トラックがDownになった瞬間、priorityが110→90に落ちる。R2側のpriority 100より下になるので、preempt有効ならR2が昇格してActiveになる、という仕掛け。decrement値は「相手のpriorityと自分のpriorityの差より大きい」が鉄則。
R1(config)# ip route 0.0.0.0 0.0.0.0 192.0.2.1 track 1 R1(config)# ip route 0.0.0.0 0.0.0.0 198.51.100.1 200
主経路はAD=1(デフォルト)でtrack付き、副経路はAD=200のfloating static。trackがDownになると主経路がルーティングテーブルから消えて、副経路が浮上する。HSRPがいない単機構成のサイトでよく使うパターン。
最低限見るべき4つのコマンド
R1# show ip sla statistics 1
IPSLAs Latest Operation Statistics
IPSLA operation id: 1
Latest RTT: 12 milliseconds
Latest operation start time: 14:32:05 JST Wed Apr 29 2026
Latest operation return code: OK
Number of successes: 142
Number of failures: 0
Operation time to live: Foreverreturn codeがOK、Number of successesが増え続けていれば正常。タイムアウトしているとここがTimeoutになる。
R1# show track 1
Track 1
IP SLA 1 reachability
Reachability is Up
1 change, last change 00:42:11
Delay up 30 secs, down 10 secs
Tracked by:
HSRP Vlan10 10R1# show standby brief
P indicates configured to preempt.
|
Interface Grp Pri P State Active Standby Virtual IP
Vl10 10 110 P Active local 10.0.0.2 10.0.0.254切替テストはISP側ルータがあれば一番リアルだけど、無ければ access-list 100 deny icmp host R1のIP host 8.8.8.8 をISP側に入れて意図的に8.8.8.8への返答を落とすのが手っ取り早い。実回線を引っこ抜いてもいいけど、戻すときに別の事故を起こしがち。
設定ミスと検出のヒント
| 症状 | 原因 | 対処 |
|---|---|---|
| SLAがずっとTimeout | scheduleコマンドを入れ忘れ | ip sla schedule 1 life forever start-time now を投入 |
| 主回線NGなのに切替らない | source-interface未指定でISP-B経由で抜けている | SLA定義に source-interface を追加 |
| 頻繁にフラッピングする | delayが短すぎ/timeoutが厳しすぎ | delay down 10 up 30、timeoutを2000〜3000に |
| HSRPだけ切替らない | decrement値が両ルータのpriority差より小さい | decrement 20以上、preempt必須 |
監視先を自社の上流ルータの管理IPにしないこと。ISP-A側のルータが死んでなくても上流の上流が死んだら、結局切り替わらない。最低でも8.8.8.8や1.1.1.1のような「インターネット側の安定した宛先」にするか、複数ターゲットを track 10 list boolean or で組み合わせる。
この記事のキモ
IP SLAは「物理リンクは生きてるけど通信が死んでる」を検出する唯一の現実解。schedule投入とsource-interface明示は必ずセットで覚える。trackのdelayでフラッピングを抑え、HSRPはdecrementを20以上にしてpreempt有効。これだけ守れば、現場で動くIP SLA冗長は組める。
よくある質問(FAQ)
Q. IP SLAを動かすのに専用ライセンスは要りますか?
基本的なICMP echoや一部のUDP echoはBase IOSでもいける。一方、jitterやVoIP系の高度なオペレーションはIP Services以上のフィーチャセットが必要。Catalyst 9300のIOS XE 17.x系ならNetwork Advantageで全部使える。古い機器は show license で要確認。
Q. プローブの間隔(frequency)はどれくらいが適切?
外向き経路の冗長監視なら5秒〜10秒でちょうどいい。1秒にすると検知は早いけどCPU負荷とトラフィックが地味に増える。100台規模で1秒間隔を全機にやったら、機器のCPUが常時5%乗ってしまった事例もある。要件次第だけど、5秒が無難。
Q. IP SLA Responderって何?要りますか?
jitterやUDP echoのような双方向測定をするとき、対向機器側で ip sla responder を有効にすると、より精度の高い遅延・ジッタ計測ができる。ただ、ICMP echoの単純な疎通監視だけなら不要。今回の構成では使わない。
Q. trackをANDやORで組み合わせられますか?
できる。track 10 list boolean or でtrack 1とtrack 2のORを取る、みたいな書き方。複数の監視先を組み合わせて「どっちか1つでも落ちたら障害」「両方落ちたら障害」みたいな判定が組める。サイトによっては必須。